VS Code Won’t Open After Unplanned Restart (Failed to deserialize the V8 snapshot blob)
VS Code Won’t Open After Unplanned Restart (Failed to deserialize the V8 snapshot blob)

PostgreSQL – BULK INSERTING from a delimited file, Most common errors in Windows
PostgreSQL – BULK INSERTING from a delimited file, Most common errors in Windows

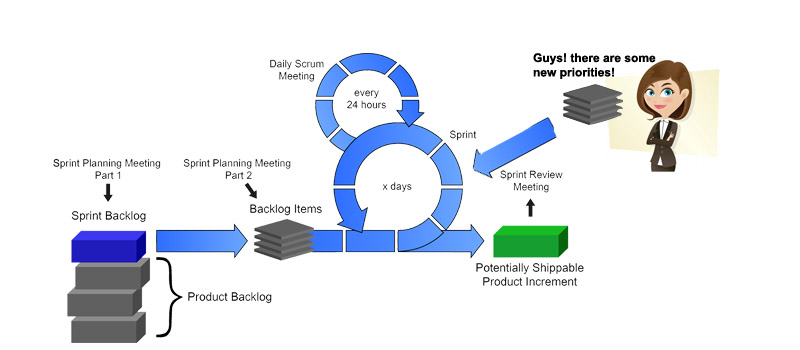
[Scrum] Adding new priorities to the current sprint
[Scrum] Adding new priorities to the current sprint
UVA 893 - Y3K Problem: Handling Python years above 9999
UVA 893 - Y3K Problem: Handling Python years above 9999

DBA bandits: Self-driving index tuning under ad-hoc, analytical workloads with safety guarantees
DBA bandits: Self-driving index tuning under ad-hoc, analytical workloads with safety guarantees
