Blog
Articles on databases, AWS, data systems, research, and practical software engineering.
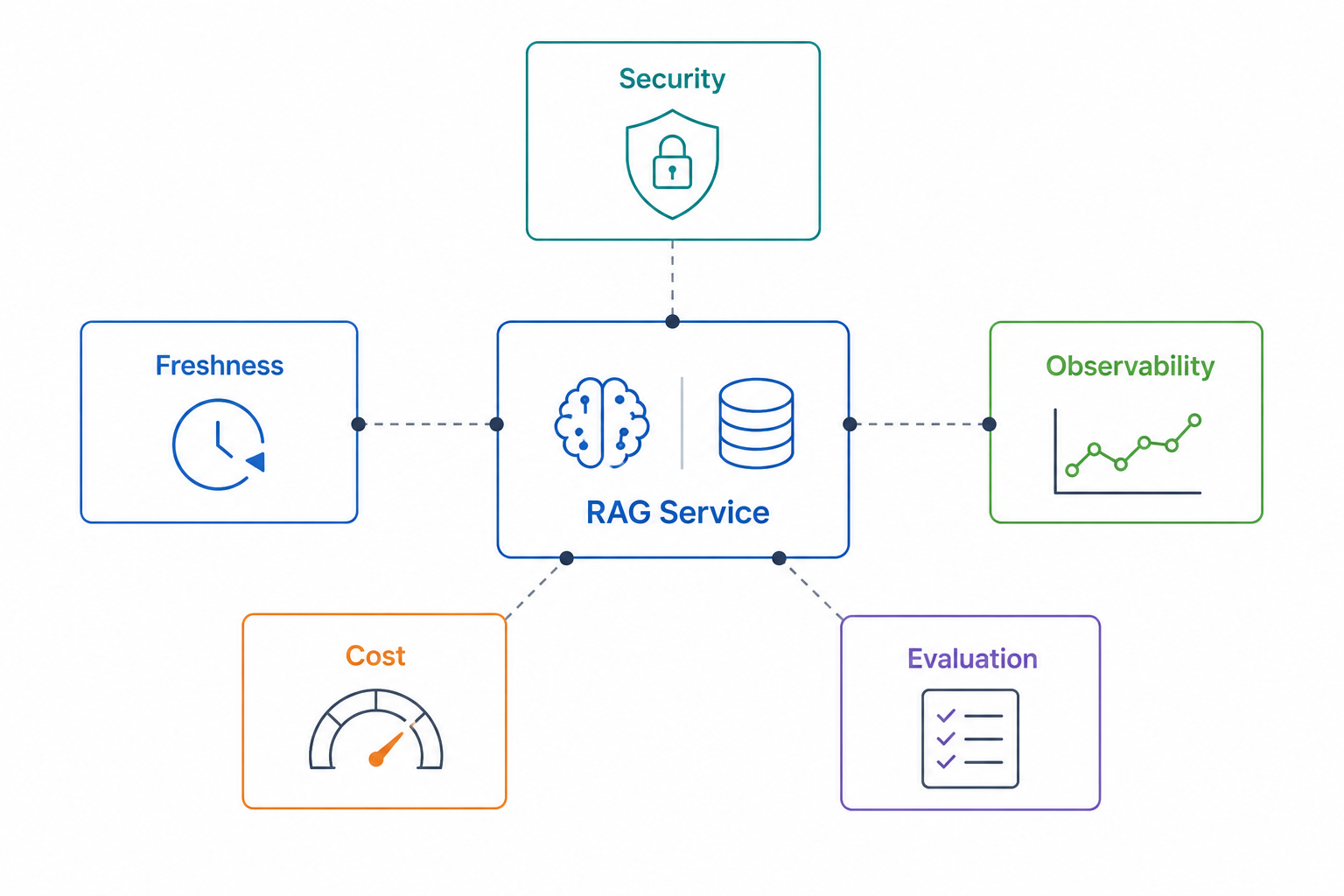
Agentic RAG with AWS 10: Production Security, Freshness, Observability, and Cost
How to operate an agentic RAG system in production without losing control of security, freshness, latency, or spend.
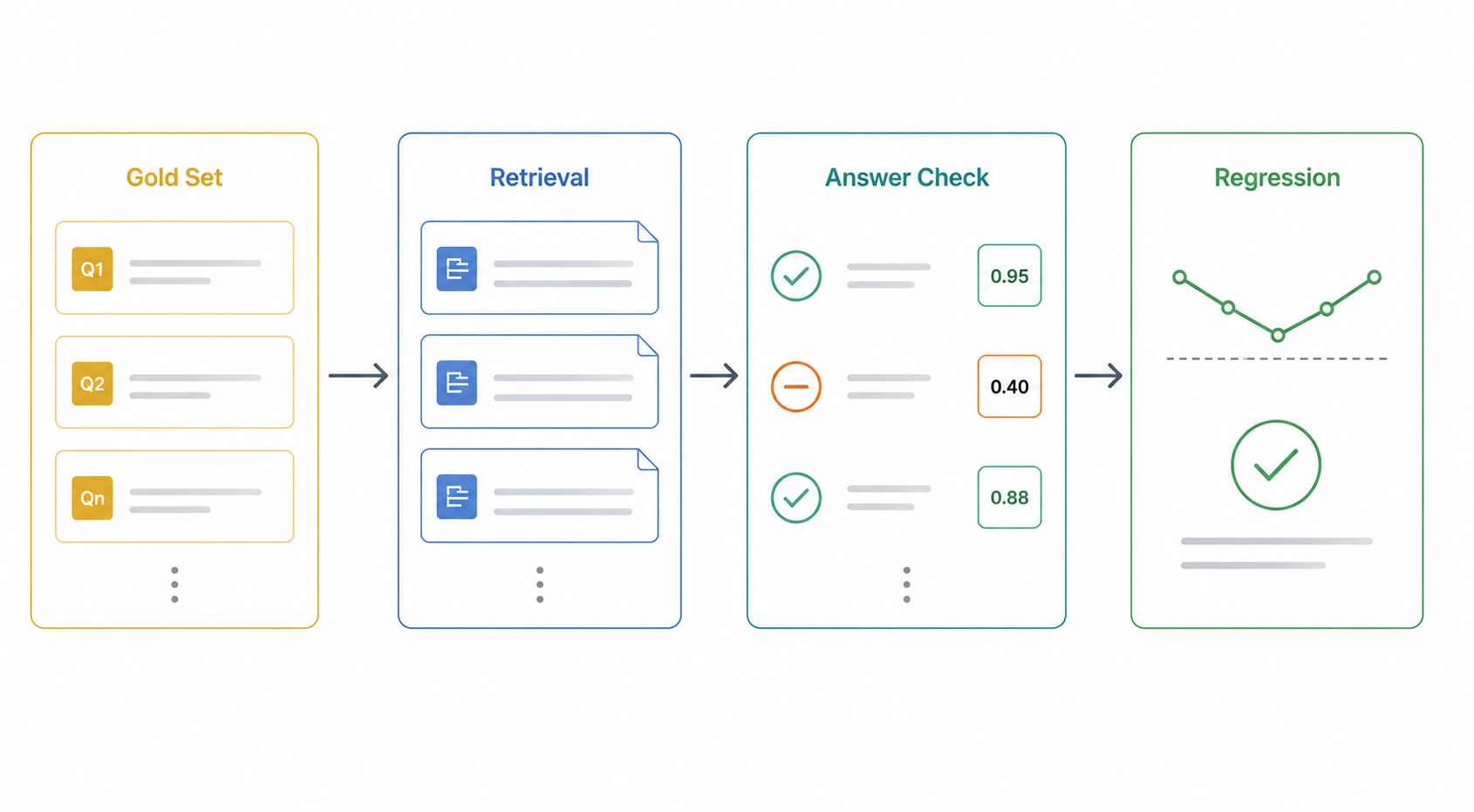
Agentic RAG with AWS 9: Evaluation, How to Know Whether the System Is Good
A practical evaluation framework for measuring retrieval and answer quality in an agentic RAG system.
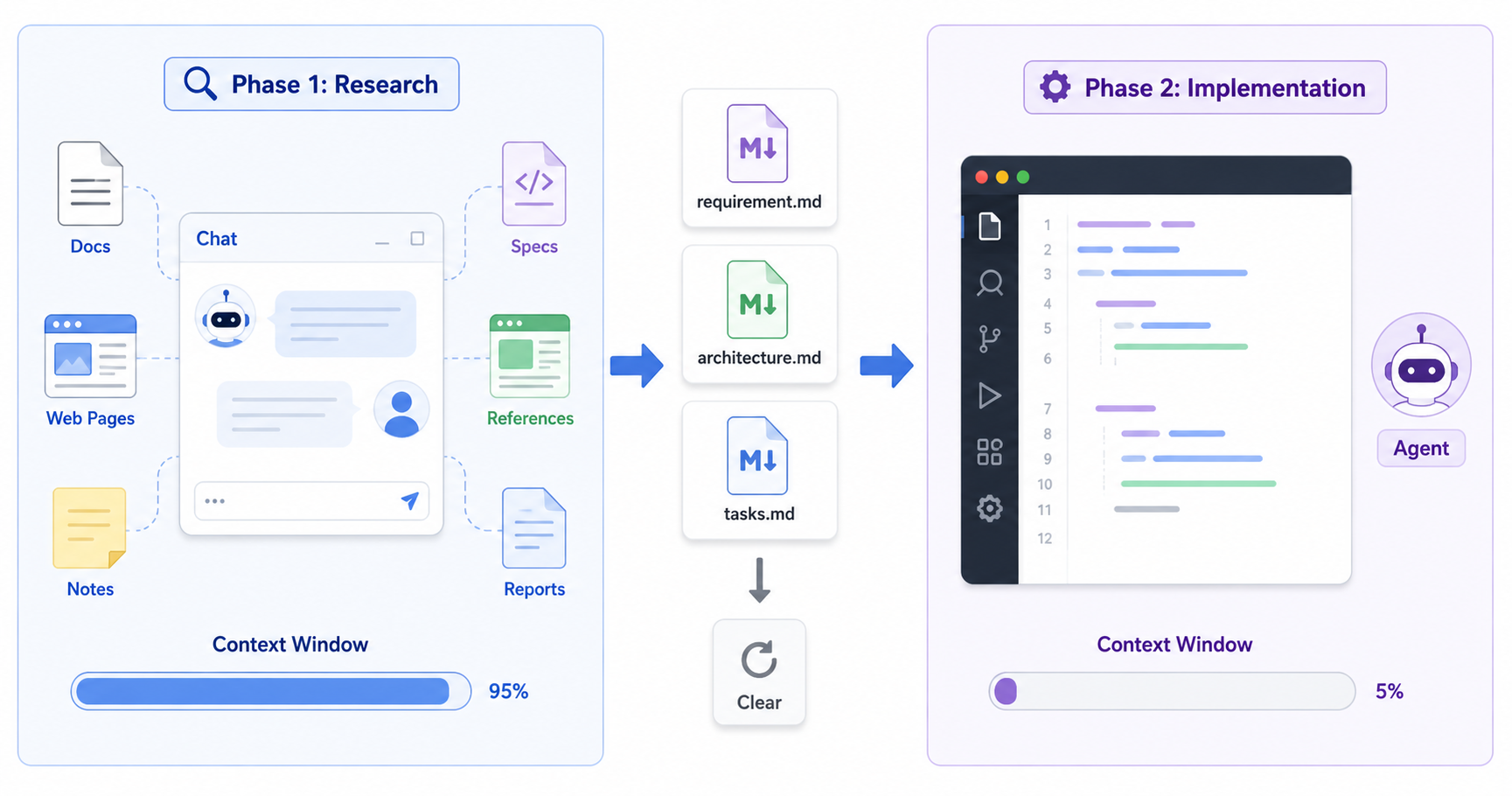
Managing Context Is the Real Skill in AI-Assisted Development
How to use context files and a two-phase workflow to get consistent output from AI agents, even on long and complex tasks.
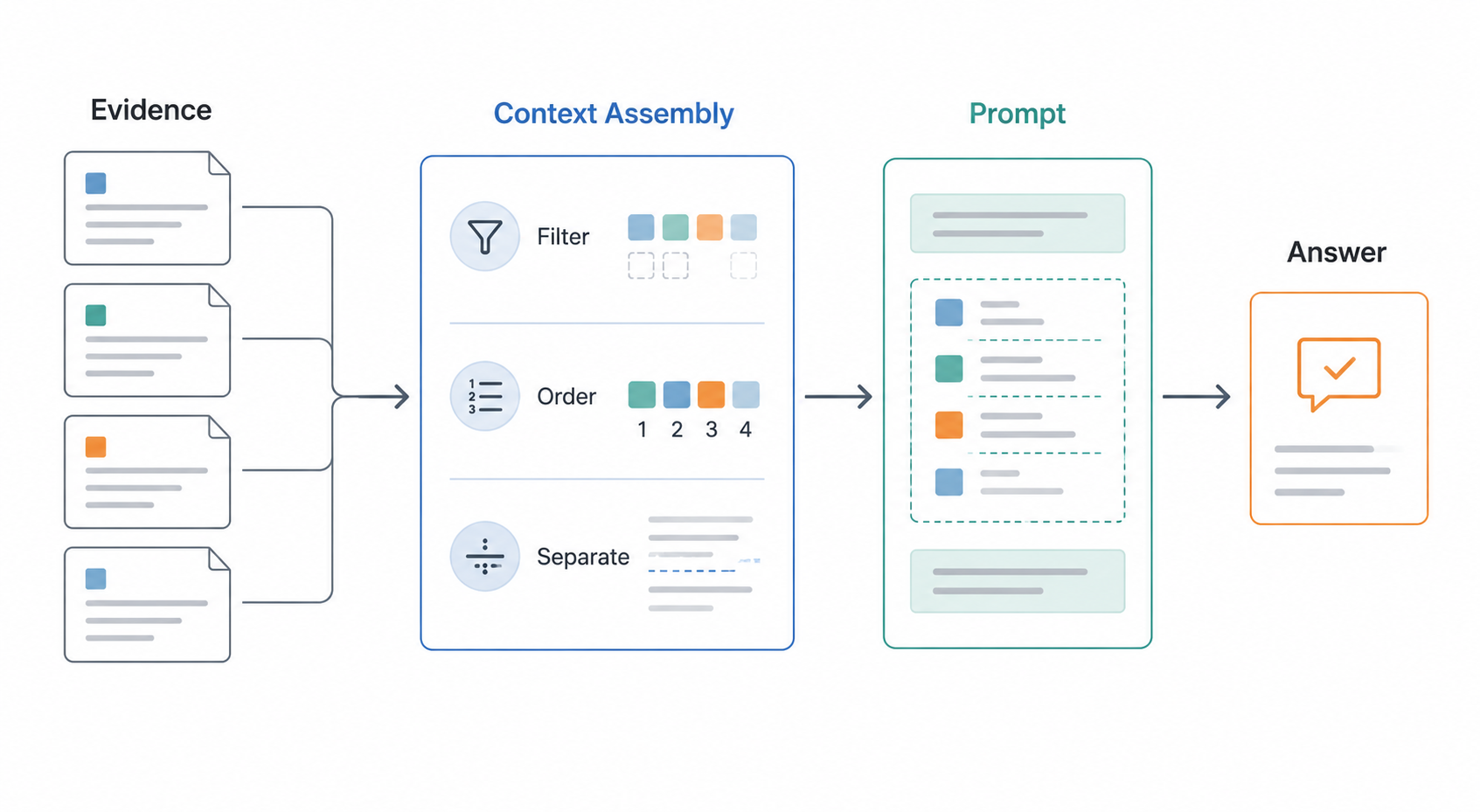
Agentic RAG with AWS 8: Prompting and Context Assembly
How to turn retrieved evidence into grounded answers without overloading the model context window.
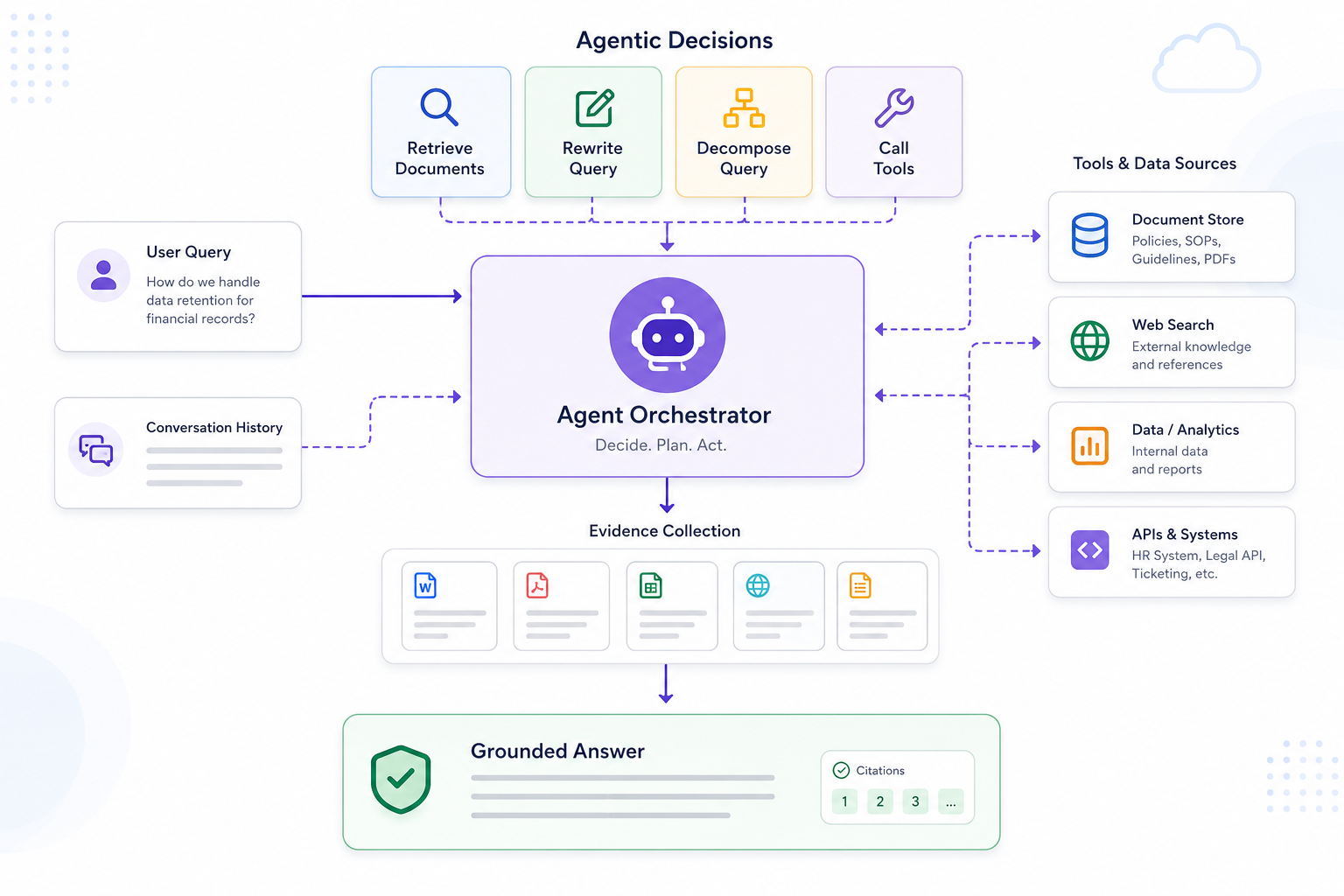
Agentic RAG with AWS 7: The Agentic Layer, Planning, Tools, and Multi-Step Retrieval
How to decide when an agentic RAG system should use iterative retrieval, planning, or tools.