Blog - page 2
Articles on databases, AWS, data systems, research, and practical software engineering.
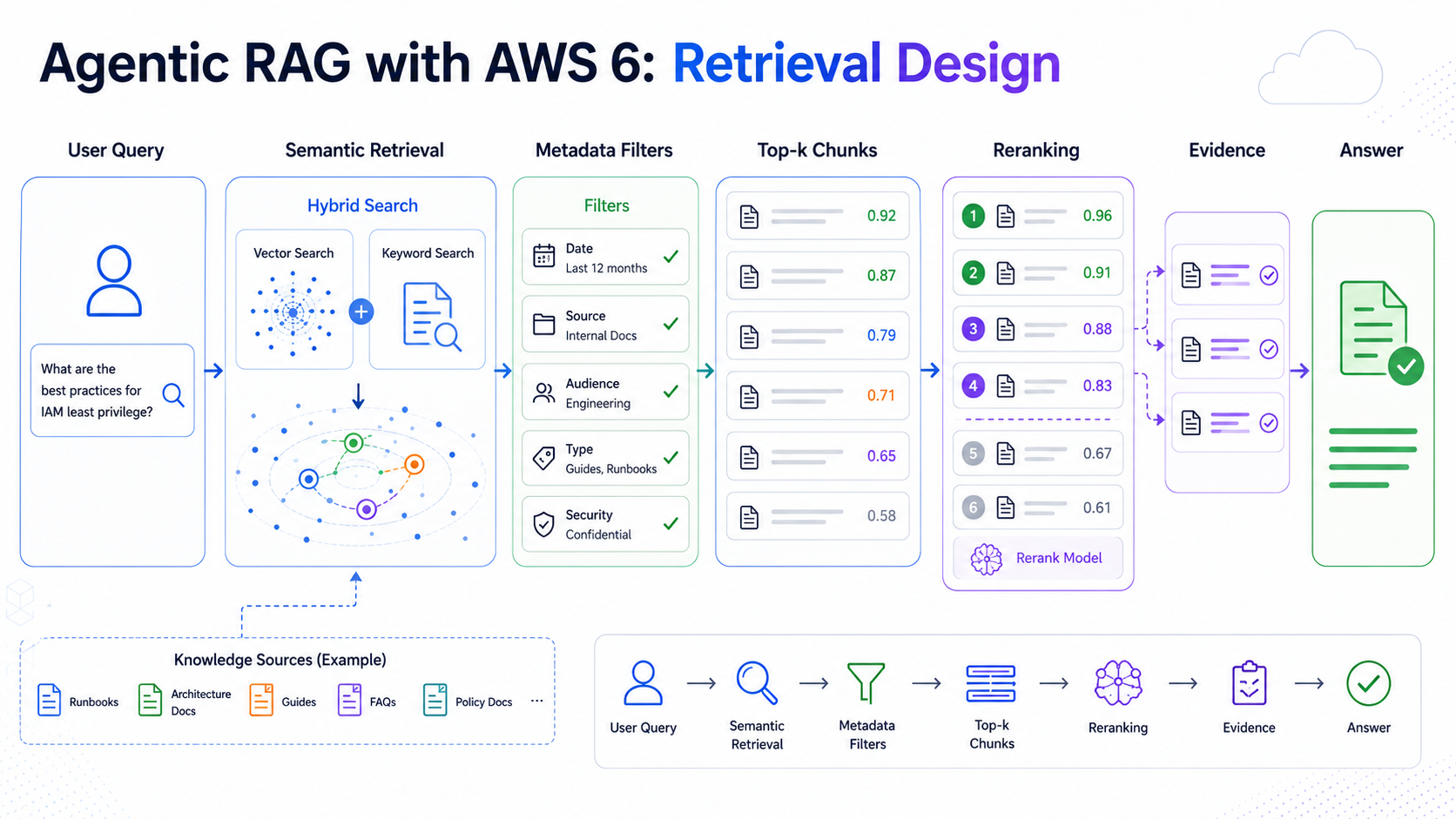
Agentic RAG with AWS 6: Retrieval Design, Top-k, Filters, Hybrid Search, and Reranking
How retrieval parameters shape answer quality in an agentic RAG system.
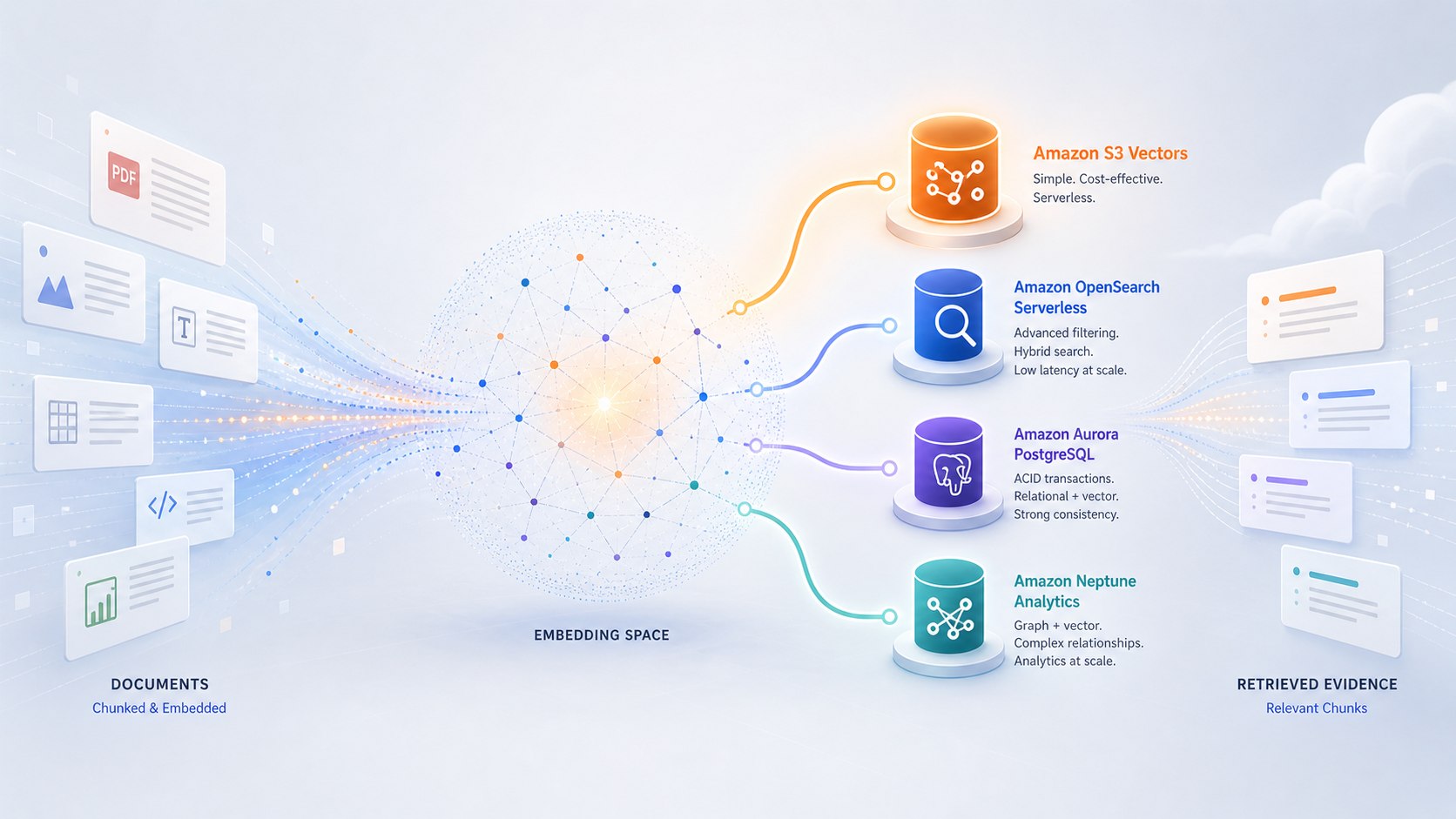
Agentic RAG with AWS 5: Choosing the Vector Database
How to choose a vector database for an agentic RAG system based on scale, filters, and operational ownership.
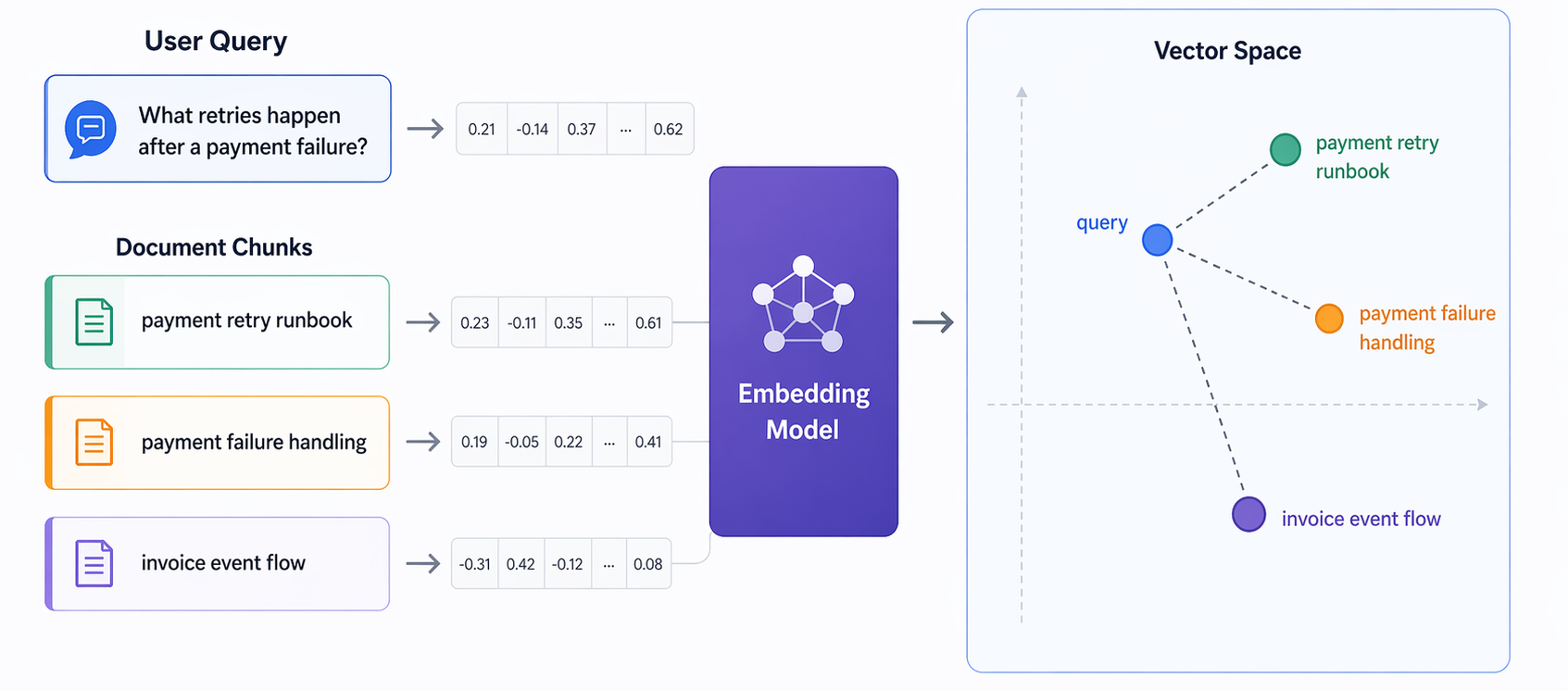
Agentic RAG with AWS 4: Embedding Model Selection
How to choose an embedding model for an agentic RAG system based on quality, latency, and cost.
Agentic RAG with AWS 3: Chunking Strategy, Size, Overlap, and Boundaries
How chunk size and document boundaries affect retrieval quality, noise, and context usefulness.

Agentic RAG with AWS 2: Documents, Ingestion, and Metadata Design
How source documents, preprocessing, and metadata choices shape the quality of an agentic RAG system.
